No code, no BB
前言
在TSRC微信群混了几个月,发现自己和大佬们最大的差距,就是没有一套牛逼的扫描器,于是思前想后,决定自己写个扫描器,毕竟对一个web狗而言没写过扫描器怎么也是说不过去的一件事。扫描器最核心的部件应该就是爬虫了,其余的扫描模块应该都是基于爬虫爬取到的URL进行的,爬虫爬得越全,那么能够测试到的攻击面也就越广。于是就花了几天时间实现了一个爬虫,这篇博客就记录下这个爬虫工具大概的设计思路和写代码过程中遇到的一些坑。项目地址
正文
0x01 Phantomjs
作为一个扫描器的爬虫组件,那么一定是要基于动态解析的。因此在设计这个爬虫之初就选择用phantomjs来作为动态页面的解析引擎,在phantomjs对页面进行渲染之后,捕获这个页面内的所有ajax请求和<a>标签的href属性值和<iframe>的src属性值,尽可能地获取到有用的URL。
Phantomjs是无界面的Webkil解析器,提供了DOM操作接口,能够方便地模拟用户操作和执行页面内的JavaScript代码。phantomjs的使用方法在这就不赘述了,下面介绍下我们需要用phantomjs来做些什么事
自动触发事件
在现实场景中,我们往往会遇到很多事件需要和用户交互后才触发,例如滚动页面加载下一页,点击某个按钮后显示一段内容等。因此就需要去模拟正常用户的操作,而正常用户操作的本质就是对页面中所有事件的触发。页面中的事件一般分两种,一种是onxxx或者javascript:xxx这样的内联事件,另一种是document.addEventListener或者jQuery中的$('dom').xxx这样的绑定事件。对于第一种情况,我们可以便利所有节点内的onxx属性和javascript:属性值,然后用eval直接执行其后面的内容
//遍历所有节点内的内联事件
function trigger_inline(){
var nodes = document.all;
for (var i = 0; i < nodes.length; i++) {
var attrs = nodes[i].attributes;
for (var j = 0; j < attrs.length; j++) {
attr_name = attrs[j].nodeName;
attr_value = attrs[j].nodeValue;
if (attr_name.substr(0, 2) == "on") {
eval(attr_value.split('return')[0]+';');
}
if (attr_name in {"src": 1, "href": 1} && attrs[j].nodeValue.substr(0, 11) == "javascript:") {
eval(attr_value.substr(11).split('return')[0]+';');
}
}
}
}
这里遇到个坑就是很多页面的事件代码中会有return false;这样的内容,如果用eval执行return是会报错的,因此需要去掉最后return的部分
对于绑定事件,我们可以用hookaddEventListener的办法,然后用dispatchevent来触发。hook的代码应该写在webpage.onInitialized内
page.onInitialized = function(){
_addEventListener = Element.prototype.addEventListener;
Element.prototype.addEventListener = function(a,b,c){
EVENT_LIST.push({"event":event, "element":this});
_addEventListener.apply(this, arguments);
};
//console.dir(EVENT_LIST);
for (var i in EVENT_LIST){
var evt = document.createEvent('CustomEvent');
evt.initCustomEvent(EVENT_LIST[i]["event"], true, true, null);
EVENT_LIST[i]["element"].dispatchEvent(evt);
}
};
然后再监听DOMNodeInserted事件获取事件触发的结果
document.addEventListener('DOMNodeInserted', function(e) {
var node = e.target;
if(node.src || node.href){
links += (node.src || node.href);
}
}, true);
拦截ajax请求
对于页面中的所有请求,phantomjs提供了onResourceRequested来进行处理,因此我们可以通过正则匹配将所有不需要的请求拦截掉,加快爬取速度,然后将需要的请求记录下来。这里采取的正则是取所有以http或https开头,不以css|jpg|jpeg|gif|png|mp4结尾的url
//处理ajax请求
page.onResourceRequested = function(requestData, request){
//过滤非HTTP||HTTPS请求
if((/^(http:\/\/|https:\/\/).+?/).test(requestData['url'])){
//过滤资源型请求
if((/.+?\.(css|jpg|jpeg|gif|png|mp4)$/gi).test(requestData['url'])){
request.abort();
}else{
console.log(requestData['url']);
}
}else{
request.abort();
}
};
表单获取
这里对于表单的处理比较粗暴,把input里的name和value作为参数键值对拼接到action的值后面形成一个url,尚未考虑是get方法还是post方法,因为如果考虑成post的话整个爬虫框架的基础数据结构就需要做调整,这个等以后再修改。
// 获取表单链接
ftags = document.getElementsByTagName("form");
for (var i=0; i<ftags.length; i++){
var link = '';
var action = getAbsoluteUrl(ftags[i].getAttribute("action"));
if (action){
if (action.substr(action.length-1,1) == '#'){
link = action.substr(0, action.length-1);
}
else{
link = action + '?';
}
for (var j=0; j<ftags[i].elements.length; j++){
if (ftags[i].elements[j].tagName == 'INPUT'){
link = link + ftags[i].elements[j].name + '=';
if (ftags[i].elements[j].value == "" || ftags[i].elements[j].value == null){
link = link + 'Abc123456!' + '&';
}else{
link = link + ftags[i].elements[j].value + '&';
}
}
}
}
links += link.substr(0, link.length-1) + '\n';
}
其他处理
写了一个相对路径转绝对路径的
// 相对地址转绝对地址
var getAbsoluteUrl = (function(){
var a;
return function(url){
if(!a){
a = document.createElement('a');
}
a.href = url;
return a.href;
};
})();
hook一些可能会导致页面阻塞的函数,例如alert,prompt,confirm等
0x02 Python
为什么选择python来做任务调度呢,因为人生苦短,我用python嘛(其实是因为只会python)。一开始用的scrapy+selenium来做后端,后来发现各种用地不顺手,不知道selenium怎么直接用phantomjs的脚本,scrapy的去重不知道怎么自定义,走了很多弯路。后来一怒之下索性就不用框架了,自己从最基础的多线程任务调度开始写,用subprocess去启phantomjs进程,再加了一个mongodb存储爬取到的数据。
多线程
一开始自己写了个线程池模块,悲剧地发现实际效果是单线程的,后来用了个现成的threadpool模块。用线程池的好处是节省了反复创建和注销线程的时间。不过后来发现这个模块没有超时处理的机制,正考虑要不要自己再来写个线程池的时候发现了subprocess模块的另一个版本subprocess32,这个模块提供了超时处理的机制,如果子线程等待时间超时,那么它会返回一个异常
try:
child = subprocess32.Popen(['phantomjs', 'phantomjs.js', url], stdout=subprocess32.PIPE)
output = child.communicate(None, timeout=30)
except Exception, e:
os.kill(child.pid,9)
return None
urls = self.duplicateFilter(output[0])
这个时候还需要去kill掉子线程启动的phantomjs进程,不然会残留一堆phantomjs进程。
去重
爬虫里URL的去重十分重要,这直接影响到了爬虫运行的效率和结果。这里的去重采取了4种层次:
- 域名不一致或不是子域名的
- 重复的URL,包括打乱参数顺序实际上仍然重复的URL
- 除了参数值其他都一致的URL
- 伪静态URL
用urlparse模块能够将URL转化为字典形式,把所有的URL做出树状结构,形如{host:{path1:[{param1:value,param2:value},{param3:value,param4:value}],path2:{}}},字典之间的比较不在乎键值对的顺序,因此第一层和第二层去重很容易实现
for r in list(set(result.split('\n'))):
if r != '':
urldict = parseurl(r).getParse()
if urldict['host'] == self.domain:
if urldict not in temp:
temp.append(urldict)
第三层去重则循环比较字典内的key值是否一致
#URL去重(去参数key相同的)
def duplicateFilter2(self, urldict):
if urldict['host'] not in self.urls:
self.urls[urldict['host']] = {urldict['path']:[urldict['param']]}
return True
else:
if urldict['path'] not in self.urls[urldict['host']]:
self.urls[urldict['host']][urldict['path']] = [urldict['param']]
return True
else:
flag = True
for d in self.urls[urldict['host']][urldict['path']]:
if urldict['param'].keys() == d.keys():
flag = False
break
if flag:
self.urls[urldict['host']][urldict['path']].append(urldict['param'])
return True
else:
return False
第四层去重在第三层的基础上,判断path的最后一段内容是否为纯数字,如果是则视其为伪静态的路径
else:
#判断是否为伪静态路径
index = self.find_last(urldict['path'], '/')
if urldict['path'][index+1:].isdigit():
urldict['path'] = urldict['path'][:index+1]
结果和对比
本爬虫在设计思路上参考了这篇文章,因此也选择跟这篇文章的爬虫做一个性能上的比较。
首先对抓取功能进行简单的测试,AISec漏洞扫描器平台提供了几个demo,基本涵盖了动态页面爬取需要做到的几个形式,爬取5层,线程设置为5,结果如下:
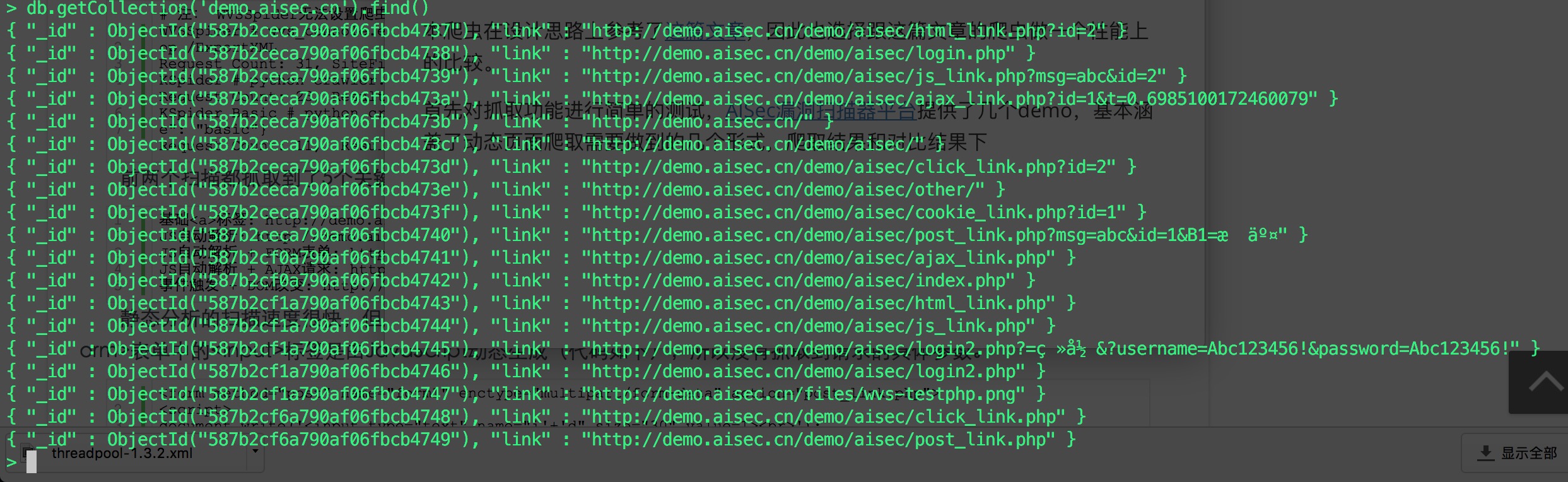 可以看到几个关键的请求
可以看到几个关键的请求
基础<a>标签: http://demo.aisec.cn/demo/aisec/html_link.php?id=2
JS自动解析: http://demo.aisec.cn/demo/aisec/js_link.php?id=2&msg=abc
JS自动解析 + FORM表单: http://demo.aisec.cn/demo/aisec/post_link.php
JS自动解析 + AJAX请求: http://demo.aisec.cn/demo/aisec/ajax_link.php?id=1&t=0.6985100172460079
事件触发 + DOM改变: http://demo.aisec.cn/demo/aisec/click_link.php?id=2
都有抓取到,同时所花费的时间如下:
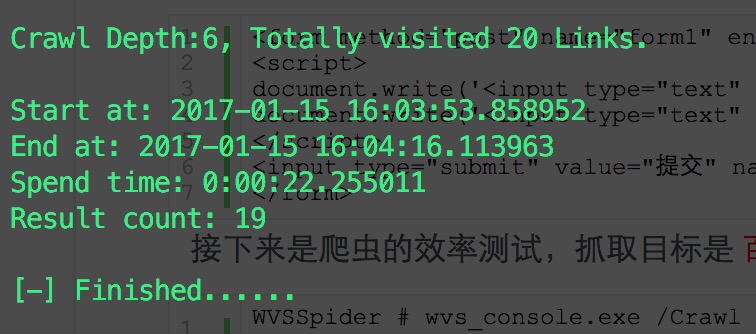 可以看到是优于那篇文章中的KSpider的,时间上领先了大概10秒
可以看到是优于那篇文章中的KSpider的,时间上领先了大概10秒
然后是效率测试,同样对百度贴吧爬取5层,线程设置为10,话费时间和爬取量如图:
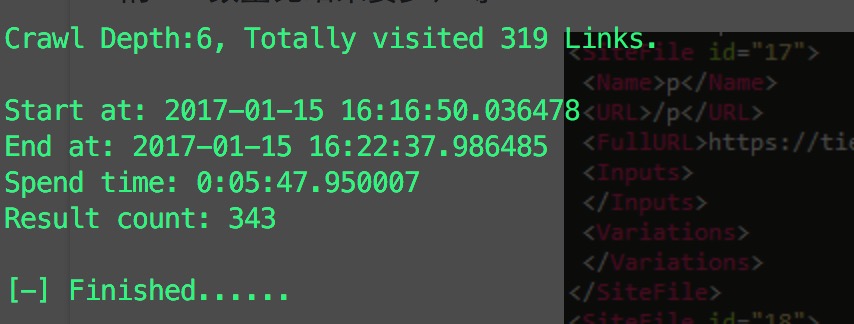 跟KSpider的结果对比发现,时间花费相近,但是爬取到的数量少些,猜测原因是我设计的访问队列和结果队列采用了同样的去重方式,如果结果队列只用第一、二层去重,那么结果数量应该和KSpider的相近。另外,访问数量也比KSpider少,估计是伪静态的判断方式比KSpider严格导致的,后面有时间再调试一下。
跟KSpider的结果对比发现,时间花费相近,但是爬取到的数量少些,猜测原因是我设计的访问队列和结果队列采用了同样的去重方式,如果结果队列只用第一、二层去重,那么结果数量应该和KSpider的相近。另外,访问数量也比KSpider少,估计是伪静态的判断方式比KSpider严格导致的,后面有时间再调试一下。
后记
感谢前面说的那篇文章的作者@吃瓜群众-Fr1day姐姐,文章给了我很多启发,特别是在phantomjs的设计上。